
こんにちは。今回は、私が現在開発している車種判別AIのために行った「車の画像収集」について、技術的な観点から紹介します。みなさんご存知の通り、AIにおいて教師データの質・量はAIのモデル精度に影響を与える重要なファクターです。その教師データを今回は効率よく大量に集めた紹介になります。
🔍 なぜ中古車サイトから画像を集めたのか?
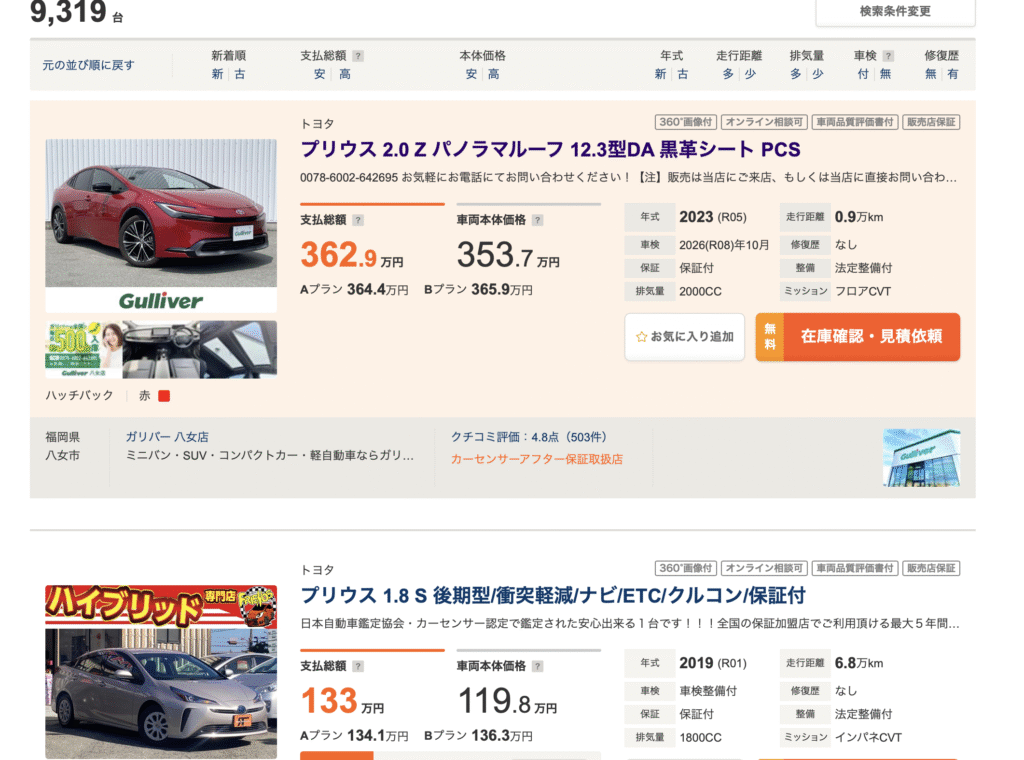
AIに車種を正確に判別させるには、大量かつ多様な画像データが不可欠です。そこで私が注目したのが中古車販売サイトです。
理由はシンプルです:
- 車種ごとに大量の実写画像が掲載されている
- 異なる角度や背景、天候のバリエーションも豊富
- 一般的な画像検索よりもラベル付きデータとして扱いやすい
これにより、現実に近い学習データを効率よく収集することができました。
⚙️ 使用技術と構成
- 言語:Python 3.x
- スクレイピングツール:Selenium + webdriver-manager
- ブラウザ操作:Chrome(ヘッドレスモード対応)
- 画像ダウンロード:urllib.request
- 前処理:ファイルサイズによるゴミ画像フィルタ
🧠 車種リストの一元管理
車種名(日本語・英語)と検索用キーワードを以下のようにまとめて管理しています。
car_list = [
{"jp_name": "トヨタ プリウス", "en_name": "Toyota Prius", "keyword": "トヨタ プリウス site:example.com"},
{"jp_name": "ホンダ フィット", "en_name": "Honda Fit", "keyword": "ホンダ フィット site:example.com"},
...
]※
site:example.comは、実際に画像を収集する中古車サイトのドメインに置き換えています。
📸 画像収集処理の流れ
- 指定の中古車販売サイトにアクセス
- 各車種ページを検索して自動スクロール
- 掲載された画像のURLを取得
- Pythonで画像を保存
- 小さすぎる画像(バナー等)は除去
if os.path.getsize(filepath) < 5000:
os.remove(filepath)🧼 ゴミ画像のフィルタ処理
今回はサイズフィルタに加えて、別スクリプトで「車が写っていない画像」「不鮮明な画像」なども後処理で除外しました。AIの学習に使えるクリーンなデータにすることが目的です。
💡 工夫したポイント
- 画像収集数(max_images)を柔軟に設定可能
- ページ遷移を繰り返して多数の車体写真を取得
- ランダムな待機時間を挿入し、Bot検知を回避
📂 今後の展望
- YOLOを使った車体の自動トリミング処理との統合
- PyTorch用にtrain/val/testへ分類するデータセット整理スクリプトの自動化
- 将来的には「車種+新車価格+中古価格」を自動表示するアプリへ発展予定!
📝 最後に
中古車サイトは、AI学習用の実用的なデータ源として非常に優れています。今回の自動化スクリプトで、必要な車種画像を高速かつ安定的に収集することができました。次回はこのデータを活用したResNetモデルによる車種分類について解説予定です!


